Data Modelling for MongoDB, Part 1 – The problem with overembedding
Overview
MongoDB is a fast, scalable, document oriented NoSQL database with flexible schemas and easy to set up failover capabilities.
But like with any tool, you need to use it correctly so that it can keep up with those promises – the best hammer in the world will fail when used as a screwdriver.
One of the most crucial parts here is a correct modelling for the individual use case. This series of blog posts will introduce you to the most common pitfalls and show you how to prevent them.
Embedding
What is embedding?
For those of you who are new to MongoDB, let's first see what embedding means. As written, MongoDB is a document oriented database. Information is stored in a format called BSON. The name's similarity to the well known JSON format is not by accident – BSON stands for "Binary jSON".
In its human readable form, a BSON document stored in MongoDB might look like this (prettified):
1{
2 "_id": ObjectId("5637933a0a55d1434116a2f7"),
3 "user": "mwmahlberg",
4 "joined": ISODate("2015-11-02T16:46:39.813Z")
5 // …
6}
Now, let us assume we are modelling our data for a social media application we call "Chirper", for my lack of fantasy and the sake of an easy grasp on the examples. Embedding allows us to store every "chirp" inside the document of a user:
1{
2 "_id": ObjectId("5637933a0a55d1434116a2f7"),
3 "user": "mwmahlberg",
4 "joined": ISODate("2015-11-02T16:46:39.813Z"),
5 "chirps": [
6 {date: ISODate("2015-11-02T16:57:36.819Z"), content:"#Chirper rocks!"},
7 {date: ISODate("2015-11-02T16:59:21.453Z"), content:"@all I am a chirper, at last!"}
8 ],
9 follows: [
10 ObjectId("5637c7140a55d1434116a2fa"),
11 ObjectId("5637c7350a55d1434116a2fb"),
12 ObjectId("5637c7350a55d1434116a2fc"),
13 ObjectId("5637c7350a55d1434116a2fd")
14 ]
15}
To be more abstract:
Embedding allows to store a valid BSON document inside another BSON document.
Why would one use embedding?
The SQL way
Put plainly: Embedding can safe you additional or (more or less) complicated queries. Let us assume we have an SQL schema like this for storing multiple phone numbers for a contact:
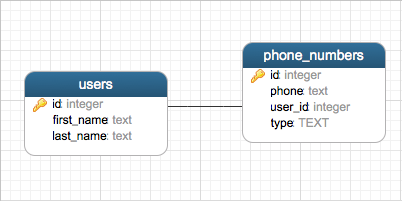
Now, in order to get all telephone numbers of John Doe, together with his full name, we have the following query:
1SELECT u.first_name, u.last_name, p.phone
2FROM users u
3JOIN phone_numbers p ON p.user_id = u.id
4WHERE u.first_name="John" AND u.last_name = "Doe"
That is already pretty complicated, although this is a pretty simple example1. As we all know, complicated things are hard to maintain, and the more complicated something gets the longer it takes to develop. A hand axe is pretty easy to produce when compared to the ISS, for example.
Please note that even in an optimal case, multiple tables and indices are involved.
The MongoDB way with embedding
Now, let's see how the document for John would look like:
1{
2 "_id": ObjectId("5637c2690a55d1434116a2f8"),
3 "name": [
4 { "first": "John" },
5 { "last": "Doe" }
6 ],
7 phone: [
8 { "type": "work", "number": "+1.234.56789" },
9 { "type": "home", "number": "+1.234.98765" }
10 ]
11}
To get all phone numbers of John, the query for mongodb would be quite simple:
1db.users.find({"name.first":"John","name.last":"Doe"})
With an index set on the name field, only the users collection is involved and only one index has to be searched.
The power of embedding
We have seen that embedding wields quite some power when it comes to answering questions in an easy way. However, there are some drawbacks, which we will see in the next chapter.
Overembedding
Actually, the "Chirper" example above shows one of the major problems with embedding. Let's assume Chirper is The Next Big Thing, totally takes off and has millions of users chirping all day.
The document size problem
With the data model above, Chirper is in big trouble now. Reason: as of the time of this writing the according MongoDB documentation states that
The maximum BSON document size is 16 megabytes.
The maximum document size helps ensure that a single document cannot use excessive amount of RAM or, during transmission, excessive amount of bandwidth.
Albeit 16 megabytes can hold a lot of follows entries and chirps, using the model shown above would artificially impose a limit on what a person can do just for the sake of comforting the developer. And we have not even started to think about answers, comments, votes, flags and alike.
The document migration problem
Note: This applies only for the mmapv1 storage engine of MongoDB. But since it is the default storage engine as of the time of this writing, I am going to adress it.
MongoDB has a paradigm that documents are never fragmented, meaning that a document is always a contiguous stream of bytes in the datafiles. In order to prevent the need of migrating a document each time some bytes are added, MongoDB applies a padding to each document2, which is empty space which will be used when information is added to the document:
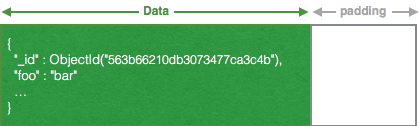
If this padding space is exhausted, the document will be migrated to a new place in the datafiles and new padding is allocated. This procedure is called "document migration" and it is a rather costly process – there is a reason why padding is added, the first place.
Now, when embedded data is constantly added to documents, this problem gets more severe, since a lot of document migrations might happen in parallel, which can -- and at some point will -- cause performance degration.
The problem of complicated CRUD
This problem coming with overembedding is a bit more subtle than the others. But it is rather easy to grasp when using deduction:
- The more complicated a model gets, the more complicated CRUD operations become.
- The more complicated CRUD operations become, the harder code becomes to develop and maintain.
- The harder code becomes to develop and maintain, the longer it needs.
- The longer development and maintenance needs, the more expensive it gets, be it monetary or time-wise (or both).
- All in all: The more complicated a model gets, the more expensive it gets, be it monetary or time-wise (or both).
One could argue that a complicated data model might pay off in the long term, but this is in fact bound to certain conditions (see below).
Conclusion
I hope I was able to show the problems overembedding brings with it. To put it a bit more positive: Embedding works if…
- …we are talking of a One-To-(Very-)Few ™ relationship, otherwise we'll hit the BSON size limit AND
- …(updates are rather rare OR you are using WiredTiger as a storage engine) AND
- …(embedding is kept rather simple and we are not talking of whole trees of subdocument arrays embedded OR those complicated models are made necessary by requirements other then technical)
Outlook
In the next article of this series, I will show how to do the data modelling properly for a One-To-(Almost)-Infinite-Many relationship. Not only the actual data modelling itself, but how to approach it, since it is significantly different than the "SQL way".
Please feel free to comment! I am eager to hear your opinion, corrections, questions (which I will try to answer) and suggestions. Also, the roadmap of this article series is not set in stone. If you want a specific matter to be discussed, do not hesitate to ask for it.
hth
Yes, there are abstraction layers which can do this for you (as long as it does not get too complicated), and one could use (materialized) views, but that only puts the solving of those problems at another place or person – and possibly out of control. ↩︎
Please see the the MongoDB docs on 'Record Allocation Strategies' for details ↩︎